sk_buff封装和解封装网络数据包的过程详解
本文共 5680 字,大约阅读时间需要 18 分钟。
可以说sk_buff结构体是Linux网络协议栈的核心中的核心,几乎所有的操作都是围绕sk_buff这个结构体进行的,它的重要性和BSD的mbuf类似(看过《》的都知道),那么sk_buff是什么呢?
sk_buff就是网络数据包本身以及针对它的操作元数据。 想要理解sk_buff,最简单的方式就是凭着自己对网络协议栈的理解封装一个直到以太层的数据帧并且成功发送出去,个人认为这比看代码/看文档或者在网上搜资料强多了。当然,网上已经有了大量的这方面的文章,但是我认为很多都太复杂了,它们都细化到了sk_buff结构体的每一个指针字段,并且还都画出了图,但一般都逃不过《》这本书的圈子。试想,如果以后内核版本升级了,字段新增了或者名字变了,怎么办?这些文章包括那本经典的《》还能有帮助吗? 因此,本文绝不深入到sk_buff的细节,但是相信这种简单的方式可以让自己在多年以后早已忘了什么是Linux协议栈的情况下,瞬间理解Linux是如何通过sk_buff封装数据包的。我们从网络的分层模型开始。网络分层模型
这是一切的本质。网络被设计成分层的,所以网络的操作就可以称作一个“栈”,这就是网络协议栈的名称的由来。在具体的操作上,数据包最终形成的过程就是一层一层封装的过程,在栈上形成一段连续的数据,我们可以称作是一层一层的push操作。同样的,数据包的解封装的过程,则可以认为是一层一层的pop操作。sk_buff的操作
要想形成一个最终的数据包,即以太帧(不考虑其它的链路层)。要进行以下的操作: 1.分配一个skb结构体2.分配数据包的数据区3.在skb数据区定位应用层起始位置4.拷贝数据到应用层(假设应用层协议没有在socket接口之上被封装)5.在skb数据区定位传输层起始位置6.设置传输层头部字段7.在skb数据区定位IP层起始位置8.设置IP层头部字段9.在skb数据区定位以太层起始位置10.设置以太头部字段可以看出基本的模式,即“定位/设置”两步骤操作,有点区别的是应用层操作,这是因为应用层的操作一般都是在socket接口之上完成的。但是既然本文讲述的是skb的通用操作,就不再区分这个了。skb的核心操作
在上面一小节,我们展示了skb的封装逻辑,但是具体到接口层面,就涉及到了skb的核心操作。1.分配skb
这个是由alloc_skb完成的,完成同一任务的接口形成一个接口族,但是alloc_skb是最基本的接口。该alloc_skb接口完成两件事,即分配skb结构体以及skb数据包缓冲区,设置初始值。size参数表示skb的数据包缓冲区的大小,这个大小包括所有层的总和。如果该函数成功返回,那么就相当于你已经有了一个大小为size的空数据包缓冲区以及操作该数据包缓冲区的skb元数据。如下图所示:

2.初始定位(skb_reserve)
skb的逐层封装的关键在于写指针的定位,即这一层从哪个位置开始写。从协议封装的压栈形象来看,这个定位应该是顺序有规律的。初始定位十分重要,后面的定位就是例行公事了。初始定位当然是定位到应用层的末端,从这里开始,逐层将协议头push到skb的数据包缓冲区。初始定位图示如下: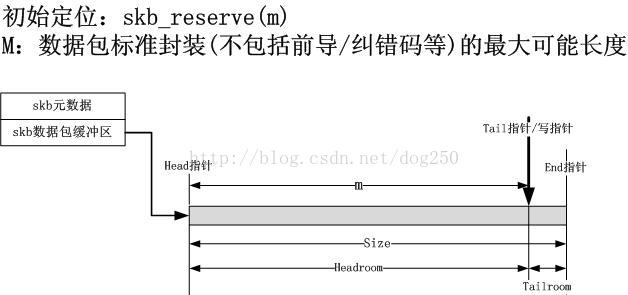
3.拷贝应用层数据(skb_push/copy)
当skb分配好了之后,需要将协议“栈”的位置定位在数据包的“最低处”,这是初始定位,这样才可以把每一层的数据或者协议头push到栈上,这个操作由skb_reserve来完成。应用层数据已经在socket之上封装好了,那么就把skb的数据包缓冲区写指针定位到应用数据的开始处,此时的写指针在应用层缓冲区的末尾,因此需要使用skb_push操作将写指针定位到应用层开始处,这等于说压入了应用层栈帧。 skb_push接口是将一个协议栈帧压入协议栈的接口,它返回一个position,该position就是skb数据包的写指针,告诉调用者,这里开始按照你的封装逻辑封装数据包,写多少字节呢?由skb_push的参数n指示。应用层的压栈操作如下图所示: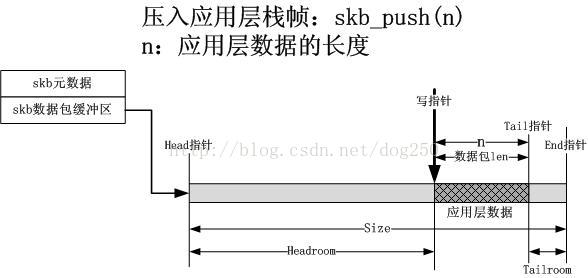
4.设置传输层头部
和应用层的操作类似,这次需要把传输层栈帧压入协议栈中,如下图所示: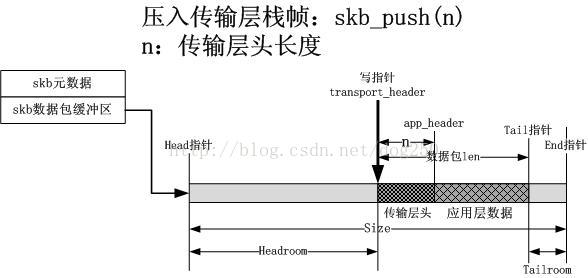
5.设置IP层头部
和应用层以及传输层操作类似,这次需要把IP层的栈帧压入协议栈中,如下图所示: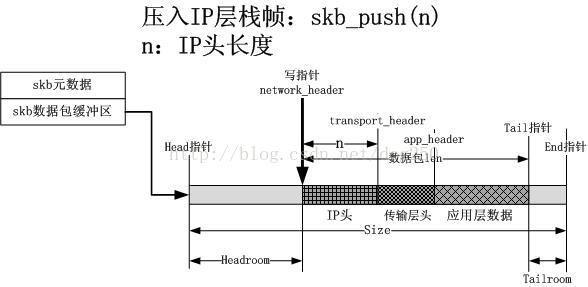
6.设置以太帧头部
这个就不说了,和上述的类似…如下图所示: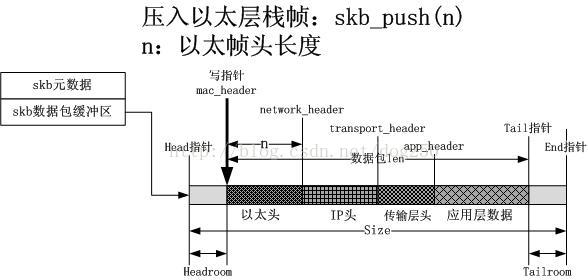
7.在应用数据后面追加PADDING
目前为止,从最后的图示上可以看到,在skb数据包缓冲区中,还有两块区域没有使用,一个headroom,一个是tailroom,这些是干什么用的呢?作为一个练习的例子,由于存在某种对齐原则,在封装完成后,我需要在数据包的最后追加一些填充,或者说我需要在最前面加一个前导码,或者最常见的,我要在数据包的最后加一个纠错码,此时应该怎么办呢?这个时候就需要headroom或者tailroom了,以在数据包最后追加数据为例,请看下图:
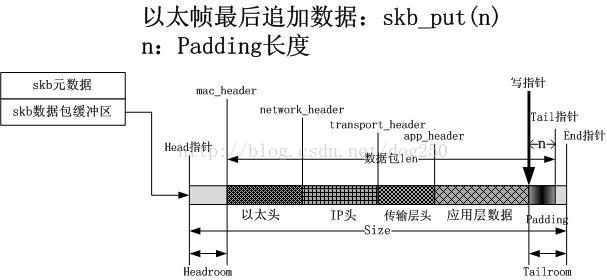
实际上,skb_put的操作就是,在数据包的末尾追加数据。至于说headroom如何使用,我就不多说了,其实还是skb_push,headroom有什么用呢?前导码,X over Y封装,不一而足。
实际的例子
下面我给出一个实际的例子,封装一个以太帧,然后发送出去:skb = alloc_skb(1500, GFP_ATOMIC); skb->dev = dev; // 例行填充skb元数据 /* 保留skb区域 */skb_reserve (skb, 2 + sizeof(struct ethhdr) + sizeof(struct iphdr) + sizeof(struct udphdr) + sizeof(app_data));/* 构造数据区 */p = skb_push(skb, sizeof(app_data));memcpy(p, &app_data[0], sizeof(app_data));p = skb_push(skb, sizeof(struct udphdr));udphdr = (struct udphdr *)p; // 填充udphdr字段,略skb_reset_transport_header(skb);/* 构造IP头 */p = skb_push(skb, sizeof(struct iphdr));iphdr = (struct iphdr*)p;// 填充iphdr字段,略skb_reset_network_header(skb);/* 构造以太头 */p = skb_push(skb, sizeof(struct ethhdr));ethhdr = (struct ethhdr*)p;// 填充ethhdr字段,略skb_reset_mac_header(skb);/* 发射 */dev_queue_xmit(skb); 解封装的过程和封装的过程相反,解封装的过程是协议栈栈帧逐层pop的过程,但是Linux协议栈并没有用栈的术语来定义接口名字,而是使用了push的反义词,即pull来定义的,skb_pull就是核心接口,和skb_push严格相对。我就不再一一画图了。 按照接口编码而不是按照实现编码
这好像是Effective C++里面的一条,同样也适合于skb的操作场景。典型的就是“如何让skb记住IP层协议头,传输层协议头,mac头的位置”,接口是:skb_reset_mac_header skb_reset_network_header skb_reset_transport_header调用时机为skb_push返回的当时。曾几何时,我按照下面的方式设置了协议头的位置:
/* 构造IP头 / p = skb_push(skb, sizeof(struct iphdr)); iphdr = (struct iphdr)p; // 填充iphdr字段,略 //skb_reset_network_header(skb); skb->network_header = p;有错吗?咋一看是没错的,但是却报错了: protocol 0008 is buggy, dev eth2 这是怎么回事?原因就在于skb纪录的协议头位置是错误的!难道以上的设置skb的network_header字段的方式有何不妥吗?当然不妥!这就是没有按照接口编码的恶果。 原因在于,系统设置skb的network_header字段的方式有两种,通过一个宏来识别:NET_SKBUFF_DATA_USES_OFFSET。也就是说,可以通过相对于skb的head指针的偏移来定位协议头的位置,也可以通过绝对地址来定位,具体使用哪一种取决于系统有没有定义NET_SKBUFF_DATA_USES_OFFSET宏,以上的skb->network_header = p明显是通过绝对地址来定位的,一旦系统定义了NET_SKBUFF_DATA_USES_OFFSET宏,肯定就不对了。既然宏定义在编译期确定,那么通过定义接口就可以在编译期唯一确定一种实现,程序员不必在乎是否定义了NET_SKBUFF_DATA_USES_OFFSET宏,这就是通过接口编程的益处。如果基于skb的实现来编程,你不得不针对所有的情况编写好几套实现,而以上错误的实现只是其中一种,而且还用错了场景!这是多么痛的领悟! NET_SKBUFF_DATA_USES_OFFSET宏是一个细节问题,如果使用接口编程便不必关注这个细节,否则你就必须搞清楚系统为何这么设计,即便这并不是你所关注的!为何呢? 由于指针的长度大小在32位系统和64位系统中是不一样的,所以按理说skb中的指针型的元数据大小也会不同,且64位系统的将会是32位系统的两倍,为了平滑掉这个差别,使元数据大小一致,就必须让64位系统的对应指针类型变为4个字节,而这是不可能的。因此在64位系统中,使用偏移来定位元数据,而偏移的类型为固定不变的unsigned int,即4个字节。为了支持上述说法,skb中加入了一个新的层次,即定义了一种新的数据类型sk_buff_data_t,该类型在编译期确定:
#if BITS_PER_LONG > 32 #define NET_SKBUFF_DATA_USES_OFFSET 1 #endif
typedef unsigned int sk_buff_data_t; typedef unsigned char *sk_buff_data_t; 节约空间之外,对于和大小相关的操作,接口实现也更加统一。这就是细节,而这些细节并不是玩网络协议栈的人所要关注的,不是吗?这完全是系统实现的层面,和业务逻辑是无关的。
为何未竟全功
本文讲述到此为止。事实上,sk_buff还有更多的,相当多的细节,但是不能再一一描述了,因为那样就违背了本文一开始的初衷,即用最简单的方式揭露本质,如果一一描述了,那么本文将成为一个文档而非一篇感悟,时隔多年以后,相信自己也不会看下去的。 关于sk_buff还有超级多的内容,仅仅结构体里面丰富字段的含义就够折腾好久的了,加上它如何配合Linux各层协议的实现,内容就更加丰富了。不过最基本的,就是本文讲述的,你得知道数据是怎样塞到一个skb并封装成一个可以被网卡实际发送的数据包的。好了,基本就是这些。最后我来总结一下本文提到的几个接口: alloc_skb:分配一个skb; skb_reserver:写指针向后移动到一个位置p,确定为数据包尾部,自始,写指针开始从该位置前移封装数据包; skb_push:写指针前移n,更新数据包长度,从它返回的位置可以写n个字节数据-即封装n字节的协议; skb_put:写指针移动到数据包尾部,返回尾部指针,可以从此位置写n字节数据,同时更新尾指针和数据包长度; …
你可能感兴趣的文章
软件(项目)的分层
查看>>
菜单树
查看>>
Servlet的生命周期
查看>>
JAVA八大经典书籍,你看过几本?
查看>>
《读书笔记》—–书单推荐
查看>>
String s1 = new String("abc"); String s2 = ("abc");
查看>>
JAVA数据类型
查看>>
【Python】学习笔记——-6.2、使用第三方模块
查看>>
【Python】学习笔记——-7.0、面向对象编程
查看>>
【Python】学习笔记——-7.2、访问限制
查看>>
【Python】学习笔记——-7.3、继承和多态
查看>>
【Python】学习笔记——-7.5、实例属性和类属性
查看>>
git中文安装教程
查看>>
虚拟机 CentOS7/RedHat7/OracleLinux7 配置静态IP地址 Ping 物理机和互联网
查看>>
Jackson Tree Model Example
查看>>
常用js收集
查看>>
如何防止sql注入
查看>>
maven多工程构建与打包
查看>>
springmvc传值
查看>>
Java 集合学习一 HashSet
查看>>